


ScrapeGraphAI: 轻松抓取网站与本地文件的 Python 库

在数据驱动的时代,网页抓取工具变得不可或缺。但传统的抓取工具有时显得僵化、难以维护。你可能遇到过这样的问题:刚刚还在正常运行的抓取程序,突然因为网站的结构改动而失效,需要不断调整和维护。为了解决这些烦恼,ScrapeGraphAI 应运而生。
什么是ScrapeGraphAI ?
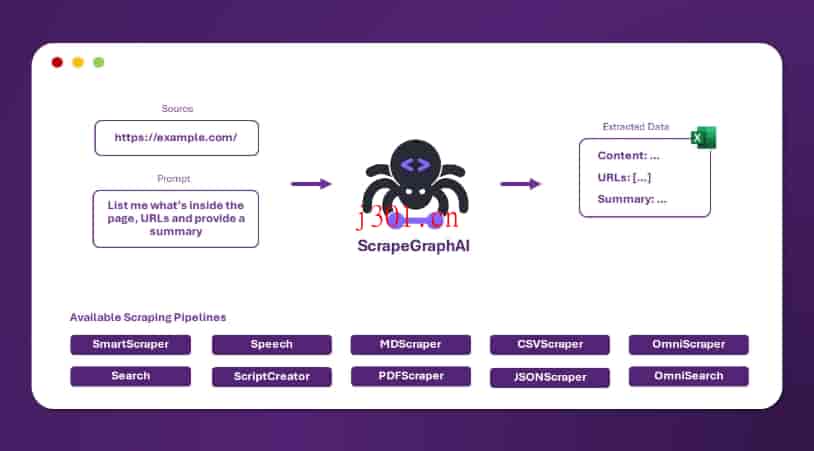
它是一个开源的 Python 库,利用大型语言模型(LLM)和图逻辑,自动化了抓取过程。你只需要告诉 ScrapeGraphAI 你想提取什么内容,它就能为你生成合适的抓取管道。
不仅支持网页,还能处理本地文件(比如 XML、HTML、JSON、Markdown 等),无论是结构化还是非结构化数据,都能从容应对。
为什么选择 ScrapeGraphAI?
与传统抓取工具相比,ScrapeGraphAI 有几个突出的优势:
1. 自适应网站结构变化
传统的网页抓取工具通常基于网站的固定模式,稍有改动就需要重新配置或调整。而 ScrapeGraphAI 借助 LLM 的强大能力,能够适应网站结构的变化,大大减少了人工干预的频率。也就是说,哪怕网站改了版面,ScrapeGraphAI 也能继续运行。
2. 支持多种数据源
无论是从网站抓取数据,还是从本地文档中提取信息,ScrapeGraphAI 都能胜任。它支持多种格式的数据文件,比如 XML、HTML、JSON 和 Markdown 等。不管你面对的是网络页面,还是内部文档,它都能轻松应对。
3. 模块化图形管道
ScrapeGraphAI 通过图逻辑为抓取任务创建动态管道,自动安排任务执行的步骤。这种设计理念不仅提高了效率,还能让开发者以更加直观的方式管理复杂的抓取流程,避免重复性工作,节省了大量的开发时间。
4.强大的 LLM 支持
ScrapeGraphAI 的核心在于其对大型语言模型(LLM)的深度集成。它支持多种 LLM,例如 GPT、Gemini、Groq 和 Hugging Face 等。此外,它还允许通过 Ollama 在本地运行模型,实现更高的定制化处理。
这些模型不仅能够理解网站结构,还能根据你的需求智能生成抓取规则,适应变化,并且不断优化提取结果。可以想象,随着模型的逐渐升级和优化,ScrapeGraphAI 的抓取能力会越来越强。
5.本地模型的灵活性
ScrapeGraphAI 还提供了在本地运行模型的能力,这样你可以不必担心数据隐私或性能瓶颈。通过 Ollama,你可以将 Hugging Face 等模型部署到自己的机器上,进行本地化数据处理,既保障了数据安全,又提升了处理效率。
使用 ScrapeGraphAI 的场景
ScrapeGraphAI 的应用场景非常广泛。以下是几个典型的使用场景:
- 数据分析与研究:从网站自动抓取相关数据,并实时更新,帮助你进行市场调研、趋势分析等。
- 电子商务:实时抓取竞争对手的网站信息,比如商品价格、库存状态,帮助你做出及时的商业决策。
- 内容管理:自动从多种数据源中抓取和整理信息,用于内容聚合平台或知识库。
- 本地文档抓取:从公司内部的文档系统中提取关键信息,无需手动操作,极大地提升了效率。
极简配置
对于开发者来说,ScrapeGraphAI 提供了简洁的 API 和详细的文档,只需几行代码即可创建出强大的抓取管道。它也支持对管道的定制化设置,灵活度极高。例如,如果你想抓取某个网站的产品信息,可能只需要这样几行代码:
python
from scrapegraphai import ScrapeGraph
scraper = ScrapeGraph()
result = scraper.fetch_data('https://example.com', 'product details')
print(result)
是的,就这么简单!ScrapeGraphAI 会根据你提供的目标,自动适配网站结构并抓取你需要的信息。
结语
ScrapeGraphAI 彻底改变了抓取工具的游戏规则。无论是从易用性、灵活性还是维护成本来看,它都展现出了极大的优势。特别是在现代数据密集型工作中,能够以如此智能和自动化的方式获取信息,简直是开发者的一大福音。
如果你还在为抓取工具频繁失效、结构复杂而感到头疼,不妨试试 ScrapeGraphAI。它的自适应能力、强大的 LLM 支持以及多源数据抓取功能,都会让你眼前一亮。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“Java面试那些事儿”或者“javatiku” 或微信扫描右侧二维码关注微信公众号
