


PRIME:探索强化学习与奖励建模的结合
PRIME是一种结合隐式奖励建模与强化学习的框架,旨在提升大语言模型的推理能力,解决奖励稀疏性和可扩展性问题。
直达下载
回到上一页 
介绍
大家有没有发现,大语言模型(LLMs)虽然在模仿数据方面很强,但在处理复杂推理问题时,还是会遇到一些“卡壳”的情况。PRIME,就是为了解决这个问题而诞生的。它通过强化学习(RL)和隐式奖励建模(PRM)的结合,为大语言模型的推理能力开辟了一条新路子。
那么,PRIME到底是什么?它又是怎么做到的呢?接下来,我就带大家一起捋一捋。
首先,PRIME的核心理念是用隐式过程奖励建模(Implicit PRM)来解决两个关键问题:一是怎么高效、可扩展地获取精准的奖励信号,尤其是密集奖励;二是如何设计有效的RL算法,充分挖掘这些奖励信号的潜力。
隐式PRM有几个亮点:
- 密集奖励:它直接学习一个Q函数,为每个token提供奖励,解决了传统强化学习中奖励稀疏的问题。
- 可扩展性:隐式PRM可以通过在线更新,仅需结果标签即可,这样就避免了分布偏移问题,还提升了扩展性。
- 简单性:隐式PRM本质上就是一个语言模型,甚至不需要额外训练一个PRM,因为SFT模型本身已经是一个很好的起点。
PRIME的实现流程可以分为以下几个步骤:
- Prompt过滤:根据策略模型的性能,保留那些准确率在0.2到0.8之间的Prompt。
- 计算隐式过程奖励:这一步会为每个token生成奖励信号。
- 更新隐式PRM:基于预测的隐式过程奖励和真实结果标签来调整隐式PRM。
- 优势估计:这里会分别计算结果奖励和隐式过程奖励的回报,并结合RLOO(Leave-One-Out)方法进行优化。
在实际操作中,PRIME的算法流程是这样的:

- 策略模型和隐式PRM都用SFT模型初始化。
- 策略模型生成rollouts(模型的输出)。
- 隐式PRM和结果验证器为这些rollouts打分,并根据结果奖励更新隐式PRM。
- 最后,结合结果奖励和过程奖励,更新策略模型。
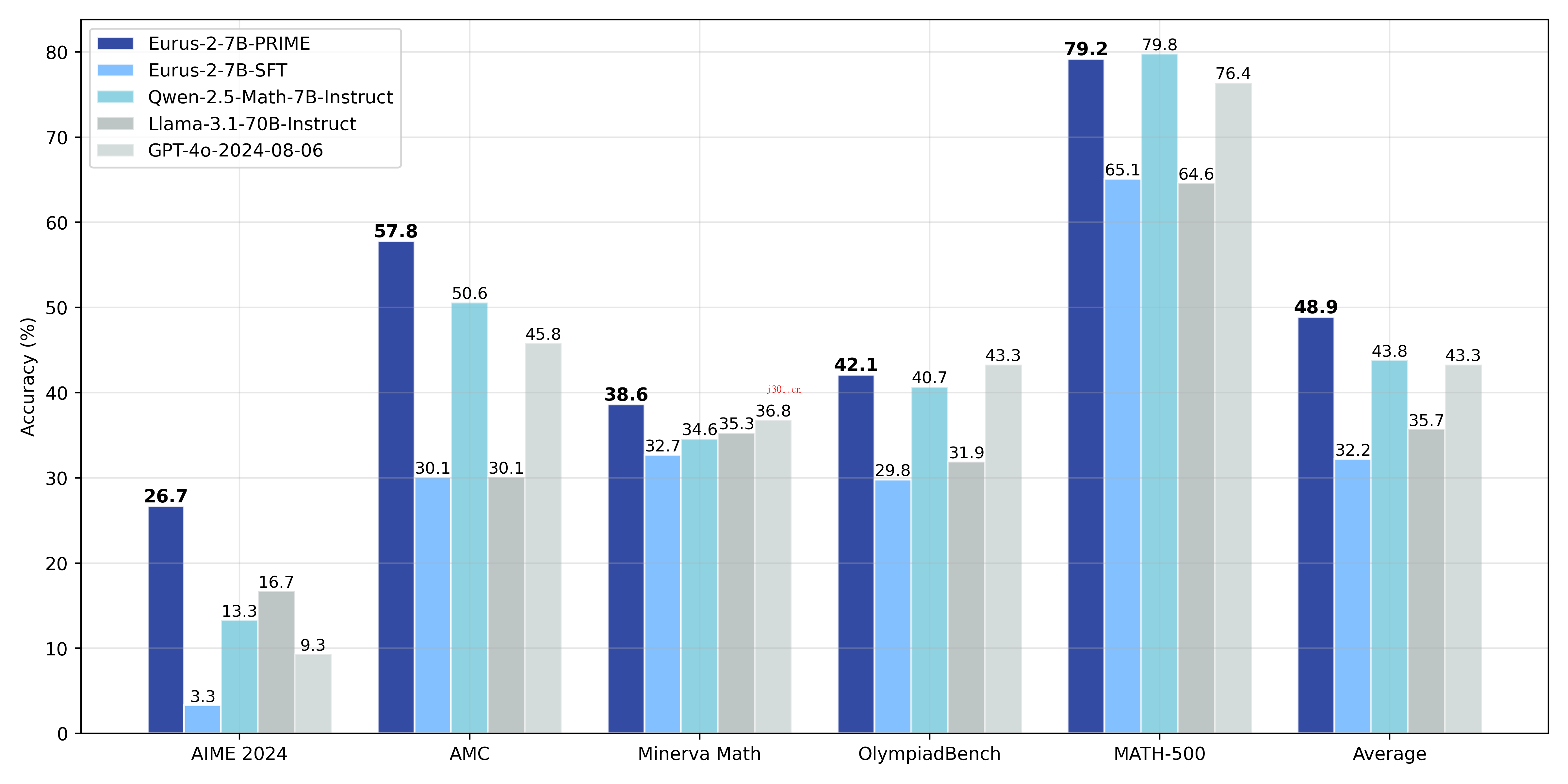
PRIME的优势在于,它不仅提升了模型的推理能力,还以一种高效、可扩展的方式解决了奖励稀疏性问题。通过这种探索驱动的方法,PRIME为大语言模型的未来发展指明了方向。
最后嘛,我觉得PRIME给人的感觉就像是为大语言模型装上了“涡轮增压器”,让它在复杂推理任务中跑得更快、更稳。如果你对强化学习和大语言模型感兴趣,不妨试试PRIME,说不定会有意想不到的收获!
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
