


Firecrawl:为AI应用提供高效数据抓取与清洗服务

在开发AI应用的时候,有没有遇到过需要从各种网站上提取干净数据的难题?Firecrawl就是为了解决这个问题而生的。它是一款强大的API服务工具,可以通过输入一个URL,自动爬取网页内容,并将其转换为清晰的Markdown格式或结构化数据。
更棒的是,它还能处理该URL下所有可访问的子页面,也就是说,无需提供网站地图,就能轻松获取整站数据。是不是听起来就很实用?
Firecrawl的使用方式非常简单。它提供了一个易用的API,用户可以通过其托管版本直接调用,也可以选择自托管的方式运行后端服务。
不仅如此,它还支持多种语言的SDK,包括Python、Node、Go和Rust等,方便开发者根据自己的技术栈选择合适的方案。而且,它还集成了多个主流的LLM框架和低代码平台,比如Langchain、Llama Index、Dify等,几乎覆盖了主流的AI开发工具链。

要使用Firecrawl的API,你需要先在官网注册一个账号并获取API密钥。有了密钥之后,你就能解锁它的各种强大功能,比如抓取网页内容并以Markdown、HTML或者结构化数据的形式返回;爬取整个网站的所有URL并提取相关内容;甚至可以进行一些复杂的操作,比如处理动态内容、绕过反爬机制、解析PDF和图片等。
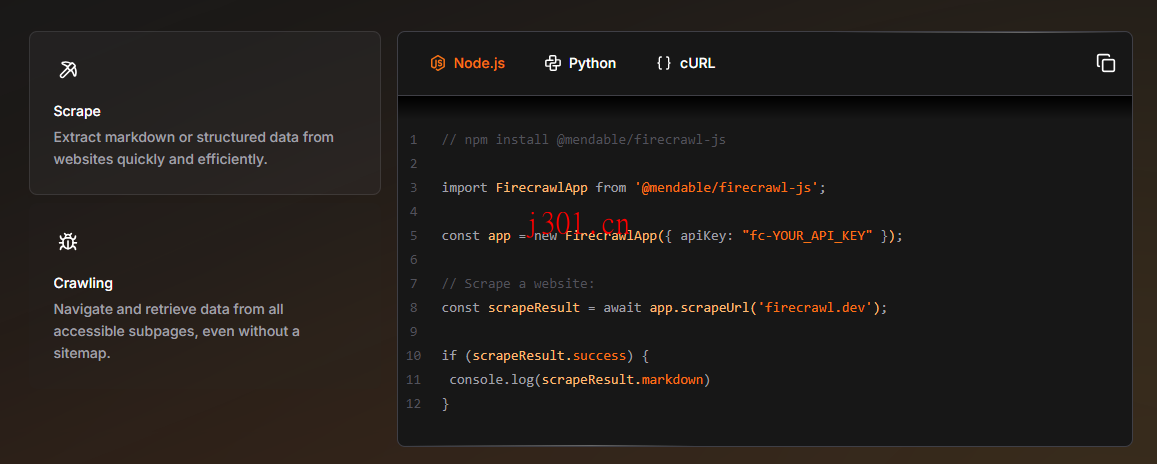
此外,它还支持定制化的功能,比如设置最大爬取深度、添加自定义头信息、排除特定标签等等,完全可以根据你的需求来调整。
Firecrawl的另一个亮点是它对复杂场景的支持能力。比如,它可以处理需要用户交互的网页内容,包括点击、滚动、输入等操作,还能在提取数据之前等待页面加载完成。对于需要批量处理大量URL的场景,它还新增了异步接口,可以同时抓取成千上万的URL,大大提升了效率。
总的来说,Firecrawl是一个专为开发者设计的高效工具,它不仅功能强大,还非常灵活,能够适应各种复杂的数据抓取需求。如果你正在为AI项目寻找一个可靠的数据抓取解决方案,不妨试试Firecrawl。我的感觉是,这款工具确实能让数据获取变得更加简单高效,尤其是它的LLM-ready格式支持,直接为后续的AI模型训练做好了准备。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
