


WebLLM:浏览器内的语言模型加速技术
WebLLM 是一个模块化的 JavaScript 包,可以在没有服务器的情况下直接在浏览器中运行并加速语言模型聊天,完全兼容 OpenAI API。
直达下载
回到上一页 
介绍
WebLLM 是一个利用 WebGPU 加速的 JavaScript 包,旨在直接在网页浏览器中部署和加速语言模型聊天。此包完全兼容 OpenAI API,意味着你可以在任何开源模型上本地使用与 OpenAI 相同的 API。
主要功能
- 模块化结构: WebLLM 本身不包括 UI 组件,而是设计为可模块化地连接到任何 UI 组件。
- 完全兼容 OpenAI API: 支持 json-mode、函数调用、流式传输等功能。
- 隐私保护与硬件加速: 在浏览器内运行,保障用户隐私的同时享受 GPU 加速的优势。
快速开始指南
安装: WebLLM 可通过 npm 包安装。建议遵循文档和入门指南来构建你的 web 应用。
npm install @mlc-ai/web-llm简单示例: 下面的代码展示了如何在网页上生成流式响应。
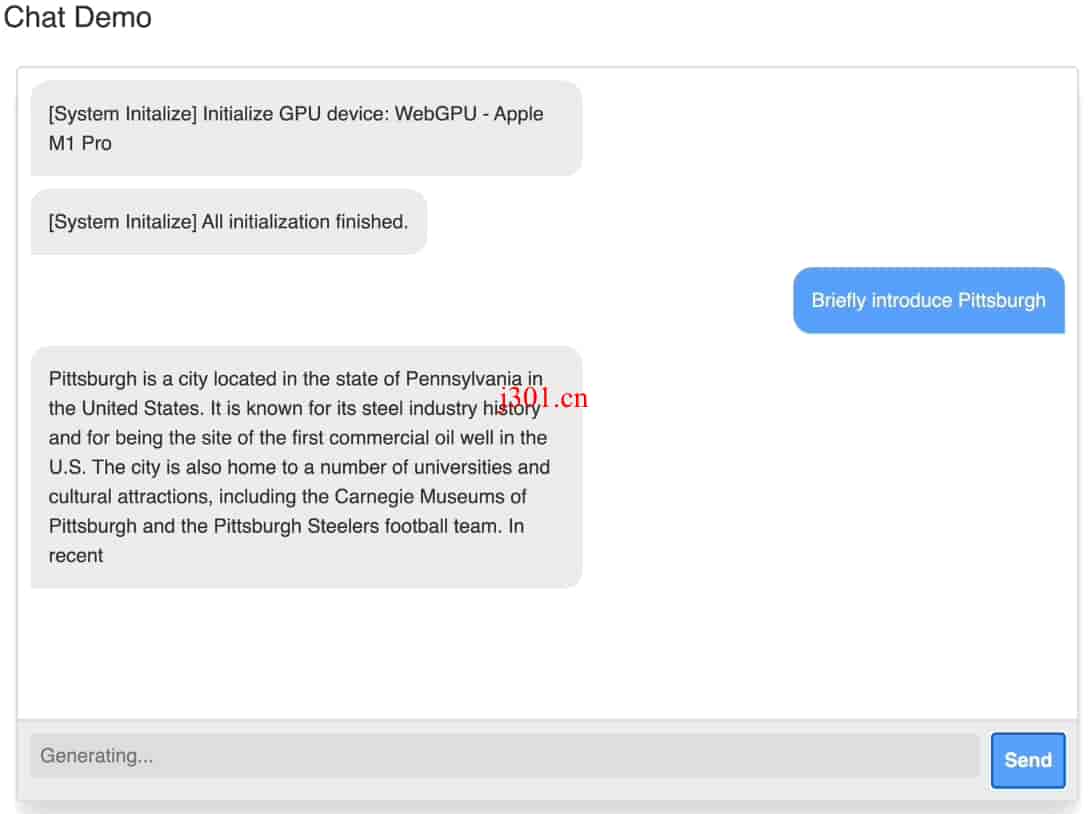
import * as webllm from "@mlc-ai/web-llm"; async function main() { const initProgressCallback = (report) => { const label = document.getElementById("init-label"); label.innerText = report.text; }; const engine = await webllm.CreateEngine("Llama-3-8B-Instruct-q4f32_1", {initProgressCallback}); const response = await engine.chat.completions.create({ messages: [{"role": "user", "content": "Tell me about Pittsburgh."}] }); console.log(response); } main();
构建 WebLLM 应用
你可以在 examples 目录下找到完整的聊天应用示例,并通过文档学习如何构建和自定义你自己的聊天应用。
扩展和定制
WebLLM 支持通过 model_url 和 model_lib_url 自定义和扩展模型和权重,使你能够部署特定的模型到你的 web 应用中。
通过 WebLLM,我能够直接在浏览器中与语言模型互动,无需依赖服务器支持,这不仅提高了响应速度,还增强了用户隐私保护。WebLLM 的模块化设计和 OpenAI API 的兼容性使得开发自定义的 AI 助手变得前所未有的简单。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
