


Hugging Face 的 Open-R1:开源复现 DeepSeek-R1 的完整路径

最近 Hugging Face 的 CEO 在 X 上宣布了一个令人兴奋的消息,那就是开源复现 DeepSeek-R1 模型的整个过程,包括训练数据、脚本等资源。而这个名为 Open-R1 的开源项目,目前已经在 GitHub 上获得了超过 17.2k 的 Star,成为了备受关注的开源复现项目之一。
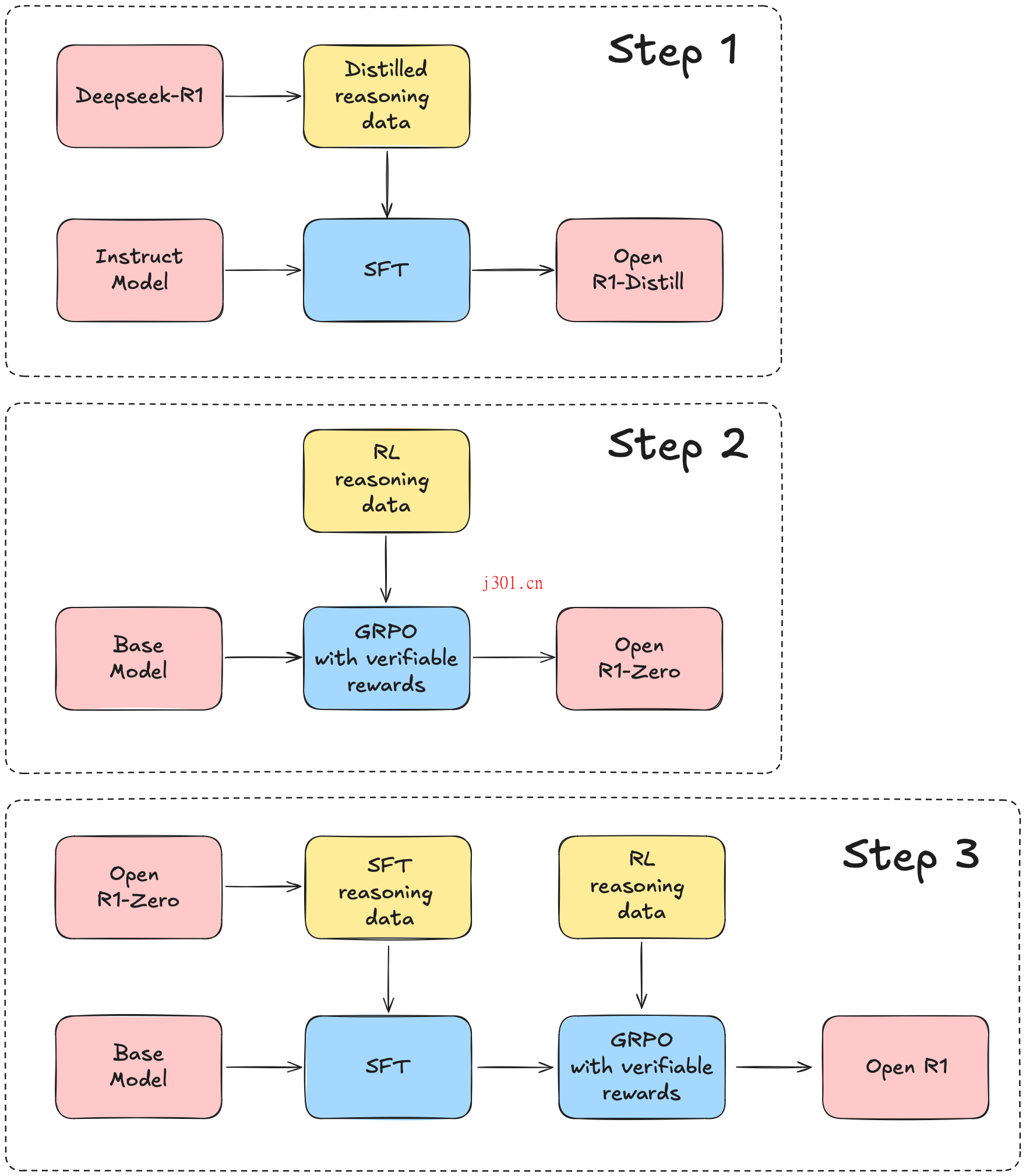
Open-R1 的目标是完整复刻 DeepSeek-R1 的技术路径,并补充那些未公开的细节。整个项目分为三个阶段:首先是蒸馏高质量推理数据集,通过从 DeepSeek-R1 中提取知识,构建一个通用的语料库;接着是验证 GRPO 算法,通过纯强化学习训练模型,无需监督微调;最后是完成多阶段的训练流程,包括基础模型训练、监督微调以及强化学习的多阶段优化。
这个项目不仅仅是简单的复现,它还尝试将框架扩展到其他领域,例如代码生成和医学诊断。通过优化代码结构和构建症状推理链,Open-R1 计划验证其在推理能力上的通用性。这样的跨领域尝试无疑为技术的广泛应用开辟了新的可能性。
具体来说,Open-R1 的代码库设计非常简洁,主要包含了一些用于训练和评估模型以及生成合成数据的脚本。例如,grpo.py 脚本可以通过 GRPO 算法在给定的数据集上训练模型,sft.py 则用于对模型进行简单的监督微调,而 evaluate.py 和 generate.py 分别用于评估模型性能和生成合成数据。此外,项目还提供了一个 Makefile,方便开发者快速运行每个步骤。
Open-R1 的开发计划参考了 DeepSeek-R1 的技术报告,主要分为三个关键步骤。第一步是通过蒸馏高质量语料库来复现 R1-Distill 模型;第二步是复现 DeepSeek 使用纯强化学习训练 R1-Zero 的过程,这需要大规模的数据集来支持数学、推理和代码等方面的训练;第三步则是展示如何通过多阶段训练从基础模型发展到强化学习优化的模型。
在评估方面,Open-R1 也取得了不错的成果。例如,在 MATH-500 基准测试中,Open-R1 的结果与 DeepSeek 报告的结果非常接近,误差在 1-3 个标准差范围内。
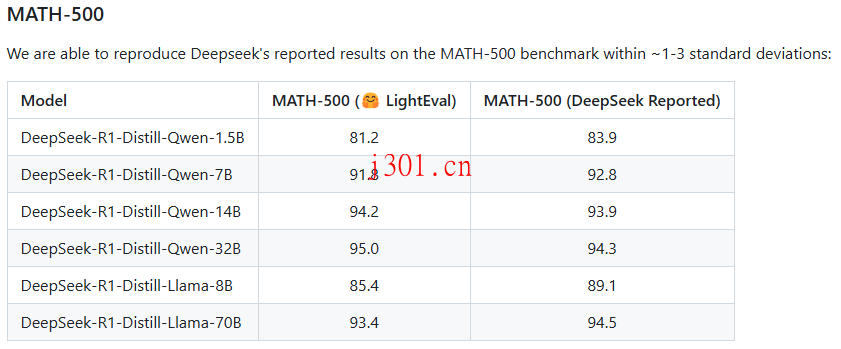
具体来说,DeepSeek-R1-Distill-Qwen-1.5B 模型在 MATH-500 上的表现为 81.2,而 DeepSeek 报告的结果是 83.9。
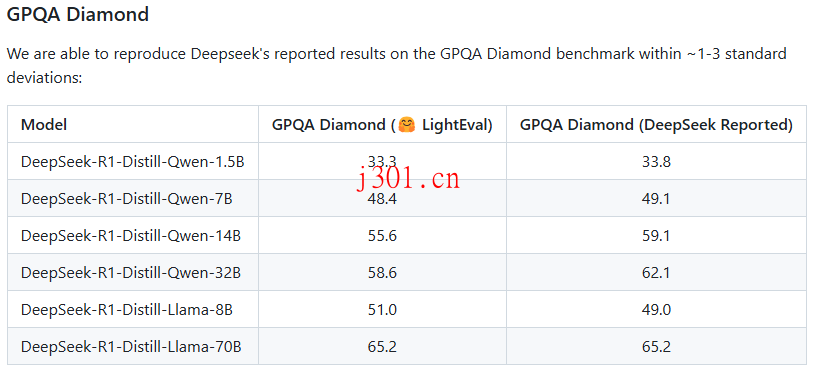
而在 GPQA Diamond 基准测试中,Open-R1 也成功复现了 DeepSeek 的结果,例如 DeepSeek-R1-Distill-Qwen-1.5B 模型的得分为 33.3,与 DeepSeek 报告的 33.8 非常接近。
如果你对这些结果感兴趣,也可以按照项目提供的命令来复现评估过程。通过设置 GPU 数量、指定模型名称和参数,使用 LightEval 工具运行评估脚本,你就能得到与官方类似的结果。当然,项目也支持通过 Slurm 作业来运行基准测试,这对于需要处理大规模模型的用户来说非常方便。
Open-R1 的开源不仅仅是一个技术复现的过程,它更是一种推动技术共享与合作的尝试。通过开源训练数据、脚本和评估方法,开发者们可以更轻松地参与到这个项目中,一起完善和扩展其功能。对于那些希望探索跨领域应用的研究者来说,Open-R1 提供了一个很好的起点。
我的感觉是,Open-R1 这个项目不仅展示了 Hugging Face 在技术上的实力,也体现了其在推动开源和技术普及上的努力。如果你对人工智能模型的训练和评估感兴趣,或者希望在代码生成和医学诊断等领域尝试新的可能性,那么 Open-R1 无疑是一个值得关注和参与的项目。

反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
