


Linly:全新中文基础与对话大模型
Linly,中文对话模型Linly-ChatFlow与基于LLaMA和Falcon的中文基础模型Chinese-LLaMA和Chinese-Falcon,提供高性能、多场景应用的语言模型。
直达下载
回到上一页 
介绍
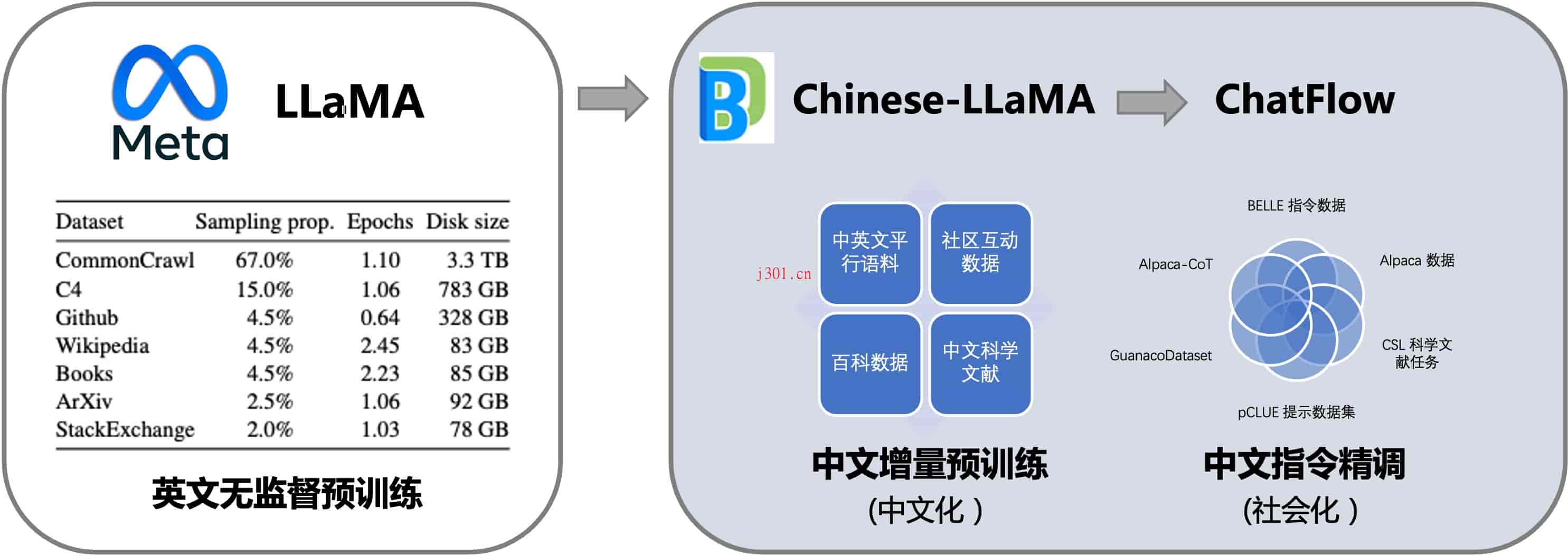
Linly系列中文语言大模型,由大数据系统计算技术国家工程实验室开发,旨在填补中文基础模型在百亿到千亿级预训练参数的空白。这一系列模型包括中文基础模型和对话模型,均基于LLaMA底座,利用中英平行语料的增量预训练,强化了模型的中文处理能力。
模型的主要优势和特性:
- 多层次训练策略:利用32个A100 GPU进行不同量级和功能的中文模型训练,确保模型的充分训练并提供强大的baseline。Linly33B是目前最大的中文LLaMA模型,提供了丰富的训练细节和实验结果以确保项目的高可复现性。
- 高兼容性与易用性:模型支持CUDA和CPU的量化推理框架,并兼容HuggingFace格式,便于广泛使用。
- 开源策略:项目公开所有训练数据、代码、参数细节及实验结果,用户可以轻松地将这些资源用于自己的研究或项目中。
模型应用概览:
- Linly-Chinese-LLaMA:以LLaMA为基础,进行高质量中文语料的增量训练,已开放7B、13B及33B版本,适用于广泛的语言理解任务。
- Linly-ChatFlow:专注于对话模型,基于400万指令数据集进行精调,提供了7B和13B的对话模型版本。
- Linly-ChatFlow-int4:4-bit量化版本,适合在CPU上部署模型推理,提高了模型在边缘设备上的应用灵活性。
未来发展方向:
项目团队正在对Linly说系列模型进行深入研发,未来将发布33B和65B的更新版本,可能带来更优异的性能。此外,团队计划通过人类反馈的强化学习(RLHF)、适用于中文的字词结合tokenizer、更高效的GPU int3/int4量化推理方法等技术进一步提升模型的效率和效果。Linly项目也将针对虚拟人、医疗及智能体场景推出更多专业化的应用模型。
这个项目不仅在技术上进行了大胆的创新,如通过全参数训练而非常见的LoRA方法,还在应用的多样性上展示了极大的潜力。特别是其对开源文化的承诺,为像我这样的开发者提供了极大的便利和机会,使我们能够在自己的项目中直接利用这些强大的模型。
×
直达下载
反爬虫抓取,人机验证,请输入验证码查看内容
请扫描上方公众号二维码,发送关键字:2024,获取验证码。
微信搜索公众号:“程序媛山楂”或者“shanzhacoder” 或微信扫描右侧二维码关注微信公众号
