


DeepSeek-V3:强大的671B参数Mixture-of-Experts语言模型

你知道吗,语言模型的世界每天都在快速进步,而DeepSeek-V3就是其中的佼佼者。这款语言模型不仅参数量大,性能也非常强悍,关键是它在效率和成本之间找到了一个完美的平衡点。

DeepSeek-V3总参数高达671B,但每次处理一个token时只激活了其中的37B参数,这种设计让它在性能和资源消耗之间达到了一个非常合理的折中。更厉害的是,它采用了多头潜在注意力(MLA)和DeepSeekMoE架构,这些技术在之前的版本DeepSeek-V2中已经得到了充分验证。
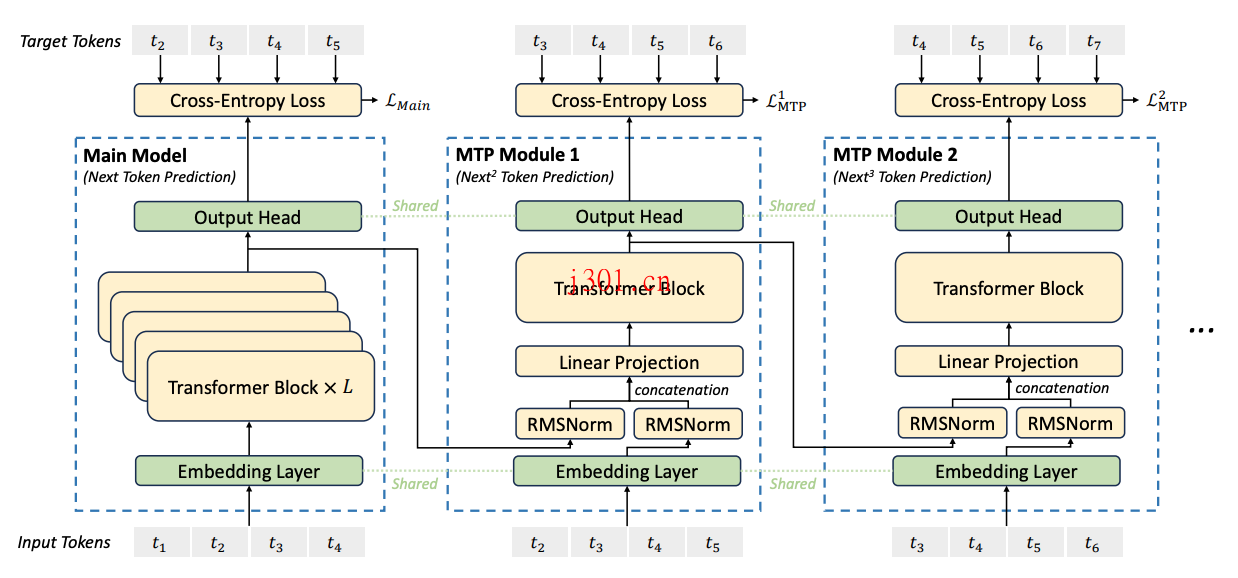
DeepSeek-V3还有一个特别的亮点,就是它摒弃了传统的辅助损失策略,使用了一种全新的负载均衡方法。这种方法不仅提升了模型的训练效率,还避免了因为强制均衡负载而导致的性能下降。此外,它还引入了多token预测的训练目标,这不仅增强了模型性能,还能加速推理过程。可以说,这些创新让DeepSeek-V3成为了一个真正意义上的高效模型。
在预训练阶段,DeepSeek-V3处理了14.8万亿个高质量的多样化token,而它的训练成本却仅为2.664M H800 GPU小时,这在超大规模模型中是非常罕见的。为了实现这样的效率,它采用了FP8混合精度训练框架,这是首次在如此大规模的模型上验证FP8训练的可行性和有效性。
同时,它还通过算法、框架和硬件的协同设计,成功解决了跨节点Mixture-of-Experts训练中的通信瓶颈问题。这种几乎完全重叠的计算和通信方式,大幅提升了训练效率,使得模型可以在不增加额外开销的情况下进一步扩大规模。
不仅如此,DeepSeek-V3还通过知识蒸馏方法,从DeepSeek-R1系列模型中提取了长链式推理能力。这种蒸馏过程将R1模型的验证和反思模式优雅地融入到DeepSeek-V3中,大幅提升了它的推理能力。同时,它还能很好地控制输出的风格和长度,让生成的内容更加符合实际需求。
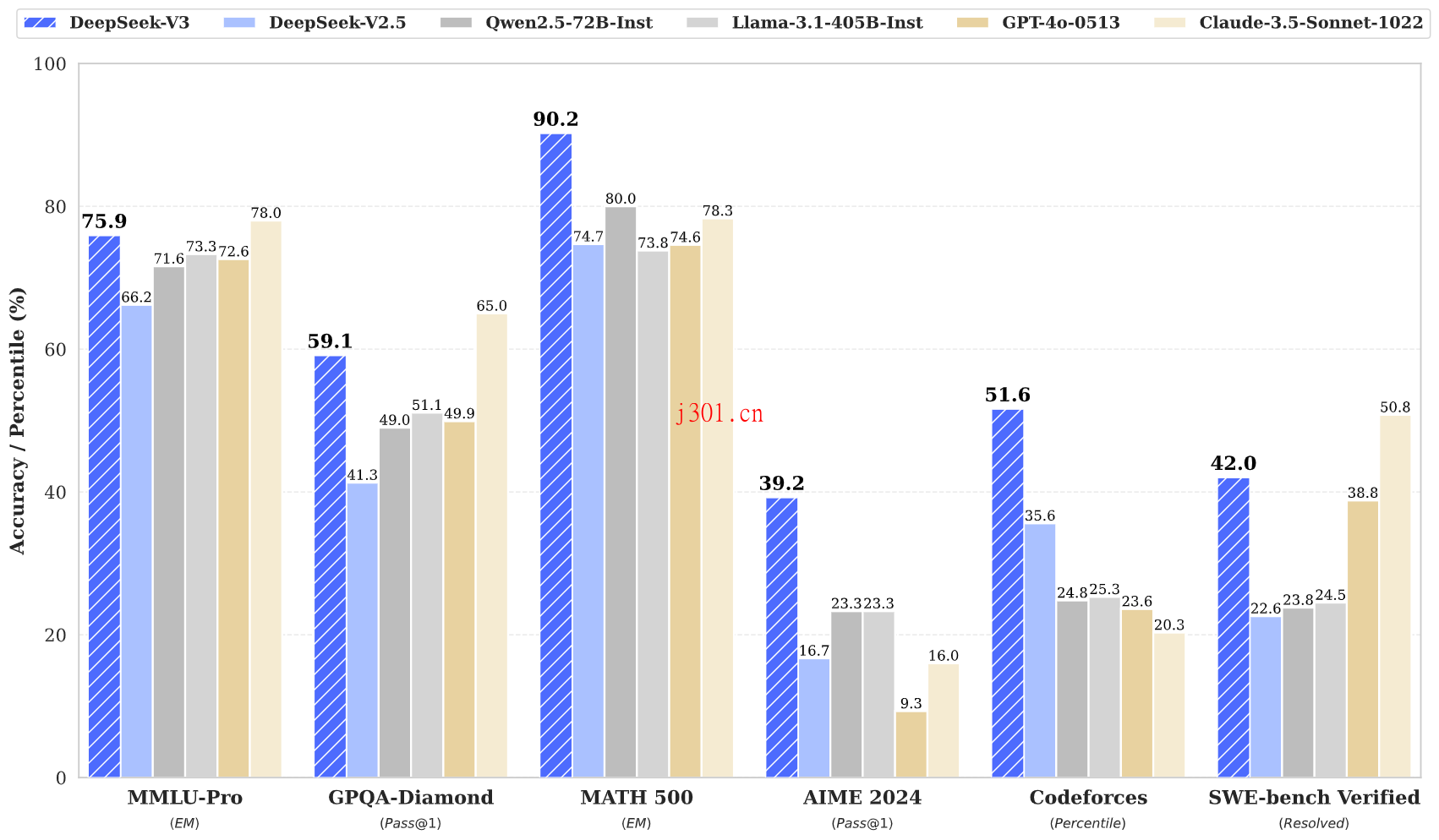
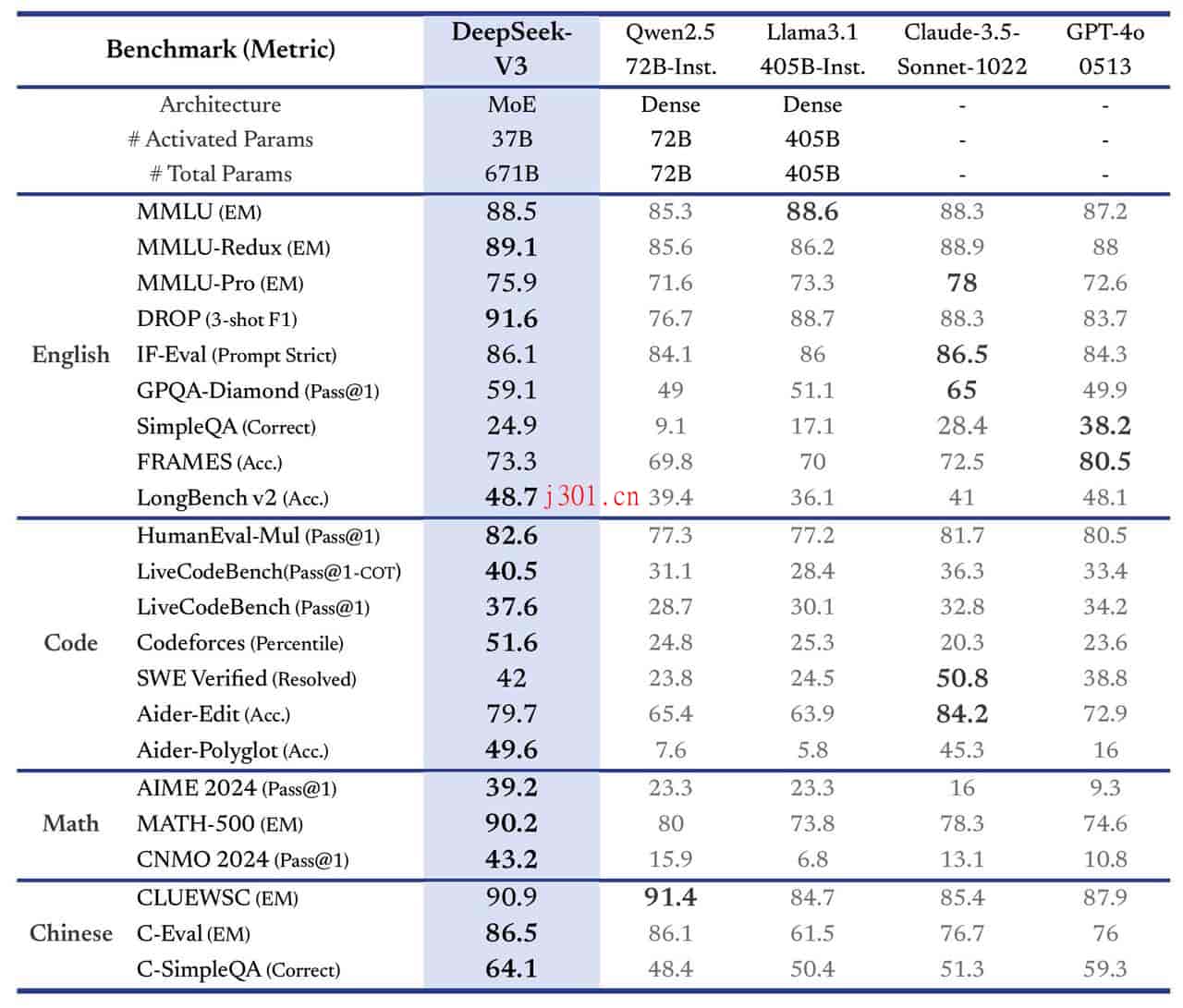
在性能评估方面,DeepSeek-V3的表现也非常亮眼。在多个标准基准测试中,它的表现优于其他开源模型,并且在某些任务上甚至接近或超越了闭源模型的表现。比如在数学和代码任务中,DeepSeek-V3的表现尤为突出,展现了其在复杂任务中的强大能力。在英语和多语言任务中,它也展示了卓越的理解和生成能力。更值得一提的是,它在推理过程中可以处理长达128K的上下文窗口,这让它在处理长文本时表现得游刃有余。
除了以上这些,DeepSeek-V3在开放式生成任务中的表现同样令人惊艳。在AlpacaEval 2.0的对话生成评估中,它取得了70.0的高分,远超其他开源模型。而在Arena-Hard的测试中,它也以85.5的得分拔得头筹。这些结果表明,DeepSeek-V3不仅在结构化任务中表现出色,在开放式生成任务中同样具有极强的竞争力。
最后嘛,我觉得DeepSeek-V3真的可以算是一个“黑科技”级的开源模型了。它的设计理念、训练效率和实际性能都让人眼前一亮。如果你对语言模型感兴趣,不妨深入了解一下这个模型,说不定会有更多惊喜等着你发现呢!
