


Code as Policies:面向体现控制的语言模型程序
Code as Policies,通过LLMs实现机器人行为策略的自动生成,提升机器人执行任务的准确性和效率。

介绍
"Code as Policies" 项目展示了如何将训练有素的大语言模型(LLMs)应用于编写机器人策略代码。这些模型能够根据自然语言命令,生成具体的控制策略代码,从而直接驱动机器人行动。
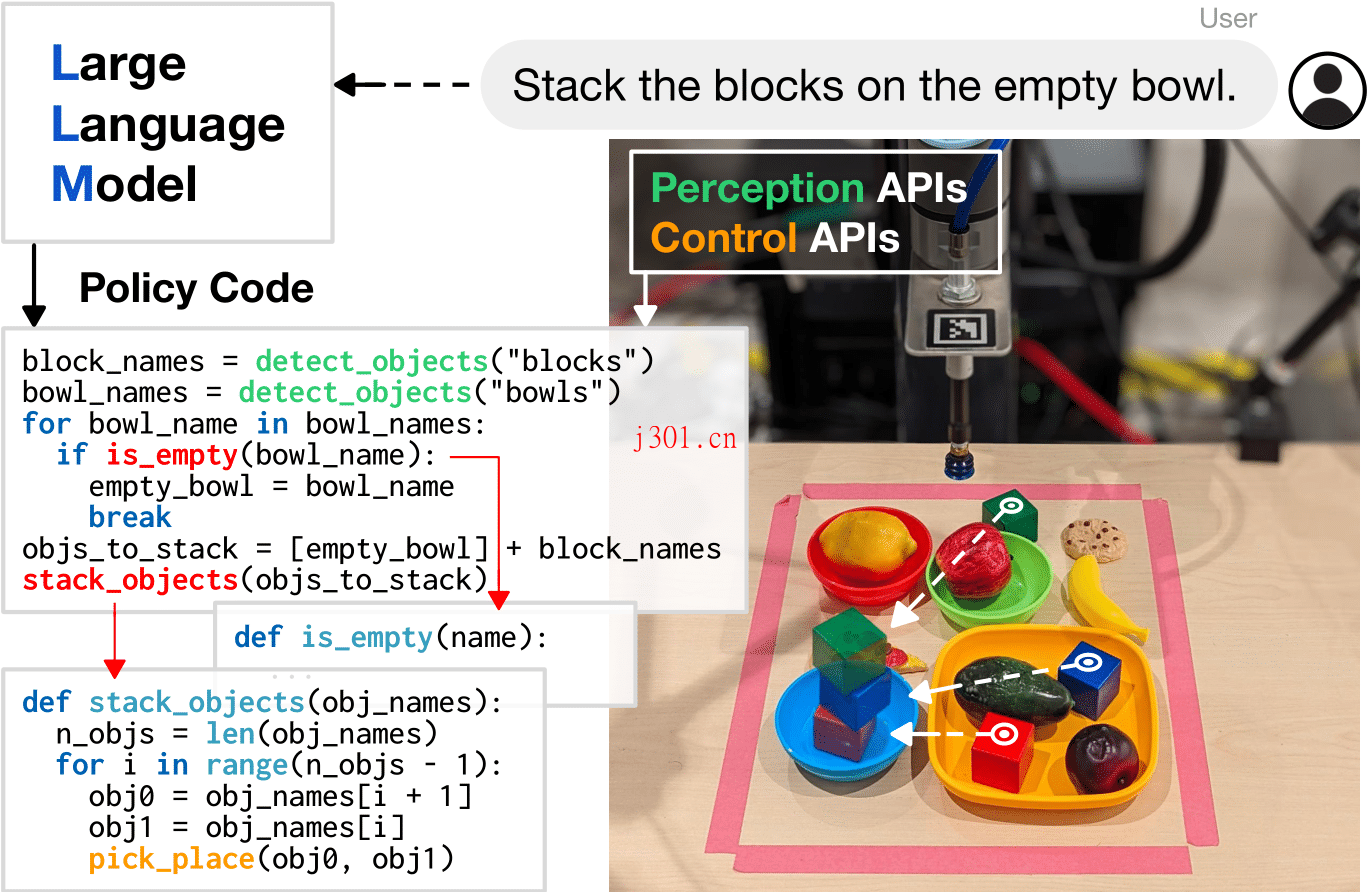
关键特性:
- 功能表达与反馈循环:策略代码可表达处理感知输出(如对象探测器)的函数或反馈循环,并参数化控制原语API。
- 代码生成与应用:通过给定示例语言命令和相应的策略代码,LLMs能够接受新命令并自动重组API调用以生成新的策略代码。
- 空间几何推理与泛化能力:使用经典逻辑结构和引用第三方库(如NumPy、Shapely)进行算术运算,使模型不仅展示出空间几何推理能力,还能根据上下文泛化新指令并给出精确的参数值。
研究成果和应用:
- 反应式策略与路径基策略:研究介绍了语言模型生成程序(LMPs)如何表示反应式策略(例如阻抗控制器)和基于路径的策略(如基于视觉的拾取和放置,轨迹控制),并在多个真实机器人平台上进行了演示。
- 分层代码生成:通过递归定义未定义函数的方式,可以编写更复杂的代码,同时提高解决 HumanEval 基准测试中39.8%问题的能力。
实验视频和生成的代码:
提供了实验视频和生成的代码示例,展示了语音和基于语音的机器人界面如何交互。代码的自动生成和逻辑展示了机器人如何理解和执行具体任务。
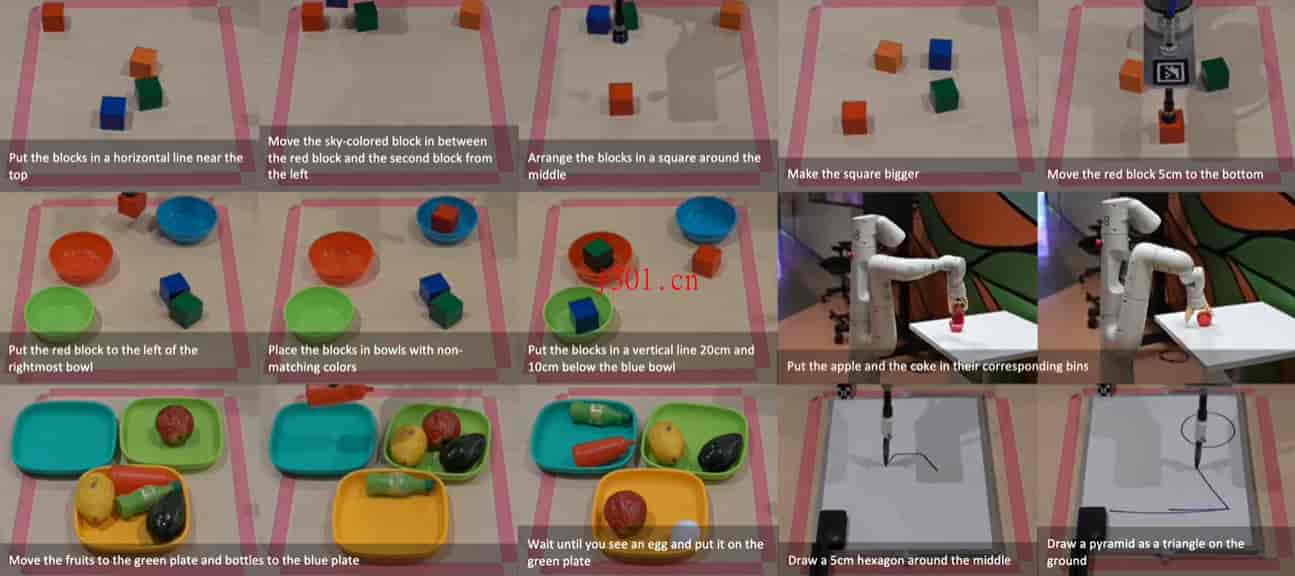
桌面操作:积木与碗
- 选择命令:用户可以从视频中选择特定命令,模型将自动生成相应的策略代码来执行任务。
- 代码示例:展示了如何将红色积木放到最右边的碗的左侧,并动态生成了用于定位和移动积木的代码。
